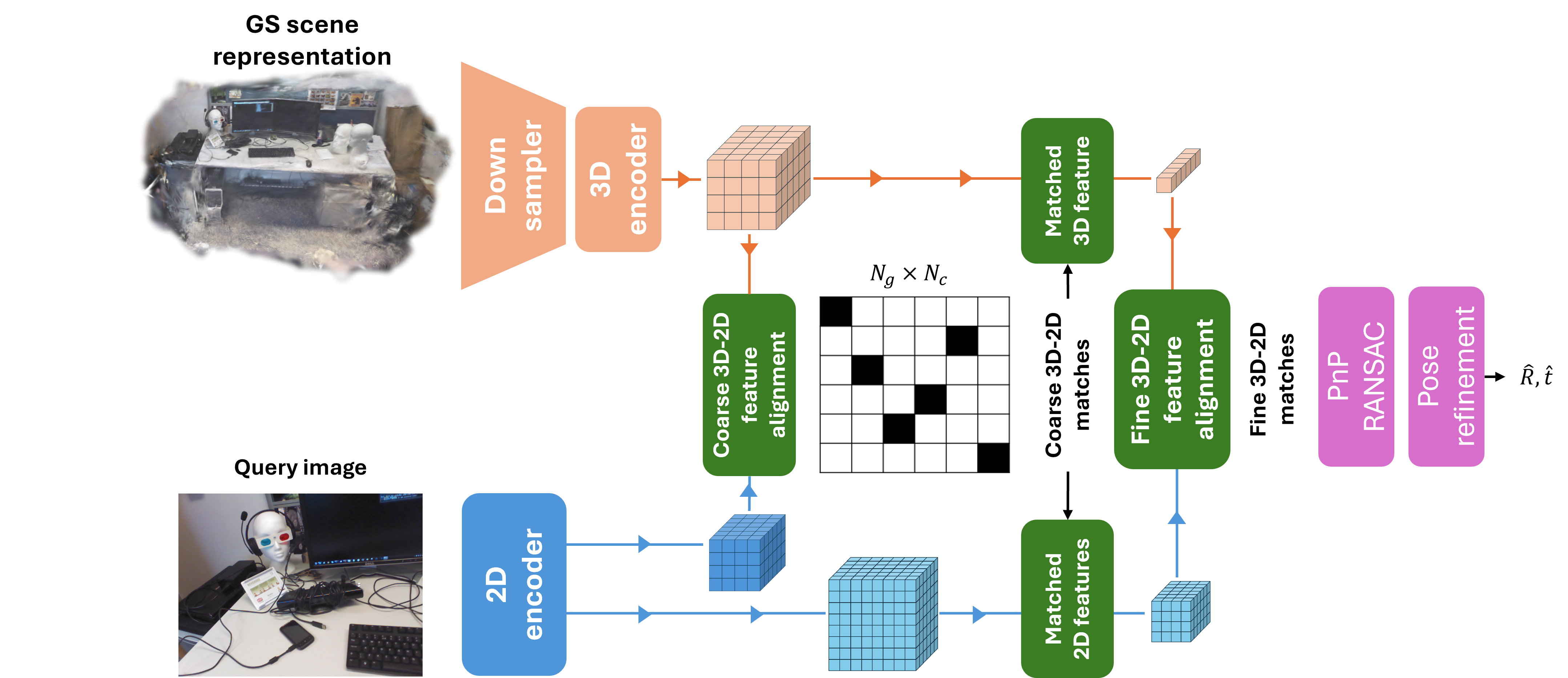
GSVisLoc: Generalizable Visual Localization for Gaussian Splatting Scene Representations

Given an RGB query image and a 3D Gaussian Splatting (3DGS) scene, GSVisLoc estimates the camera pose by matching 2D features with 3D Gaussian descriptors, followed by a 3DGS-based pose refinement step.